

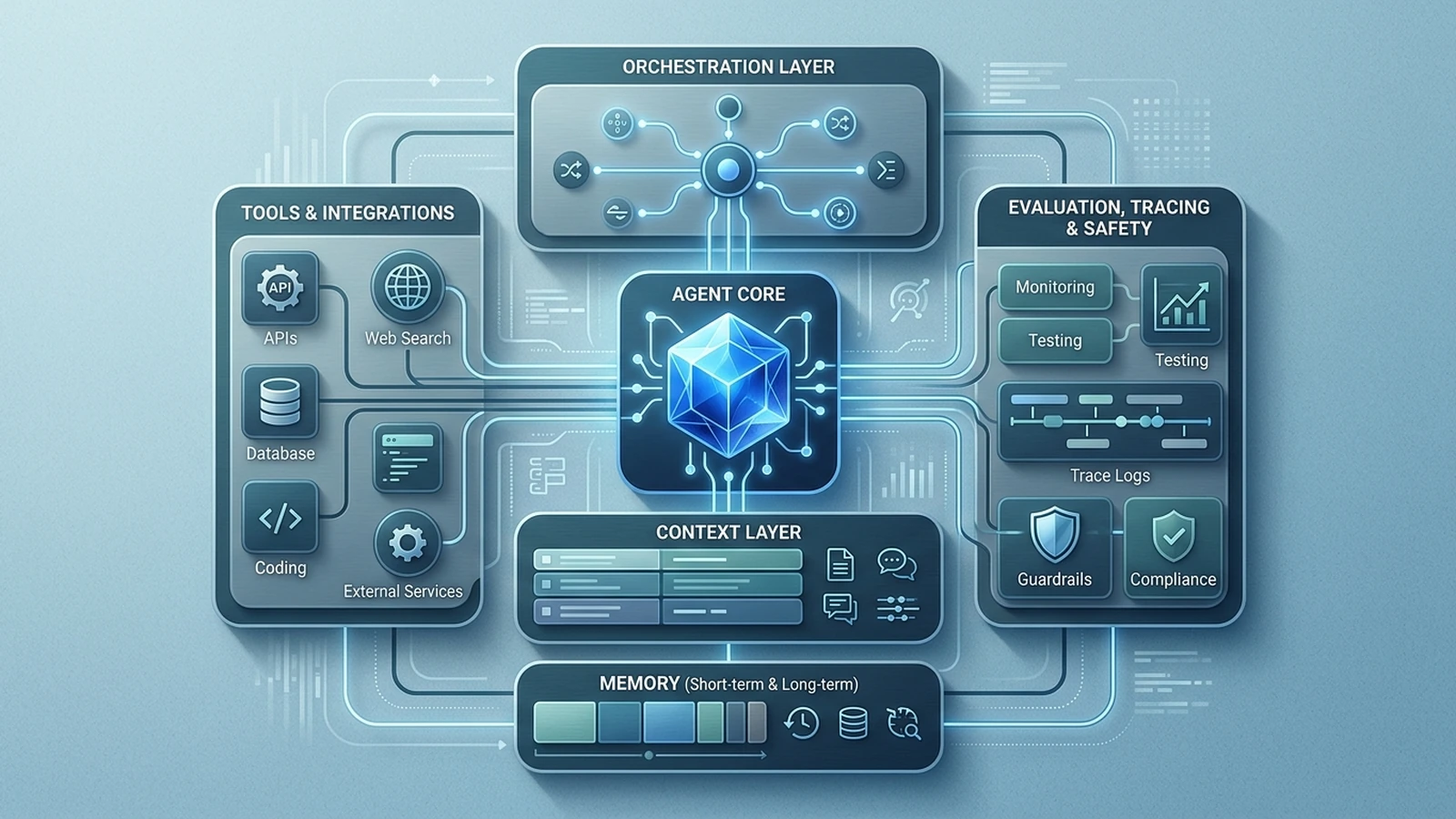
结论先说。
如果你最近在做 Agent,我觉得最容易踩的坑,不是模型不够强,而是太早把注意力放在模型本身,反而忽略了更影响结果的那几层工程系统:验证、上下文、工具、记忆和边界控制。
我刚看完 Tw93 那篇《你不知道的 Agent:原理、架构与工程实践》,里面有不少内容我挺认同。但我不想再把原文复述一遍,这篇我只提炼我觉得最值得带回项目里直接用的部分。
如果只记一句话,就是:
Agent Loop 很小,真正决定系统能不能跑稳的,是 Loop 外面的工程设计。
1. Agent Loop 其实没那么神秘
文章里给了一个很典型的 Agent Loop:
const messages: MessageParam[] = [{ role: "user", content: userInput }];
while (true) { const response = await client.messages.create({ model: "claude-opus-4-6", max_tokens: 8096, tools: toolDefinitions, messages, });
if (response.stop_reason === "tool_use") { const toolResults = await Promise.all( response.content .filter((b) => b.type === "tool_use") .map(async (b) => ({ type: "tool_result" as const, tool_use_id: b.id, content: await executeTool(b.name, b.input), })) ); messages.push({ role: "assistant", content: response.content }); messages.push({ role: "user", content: toolResults }); } else { return response.content.find((b) => b.type === "text")?.text ?? ""; }}这段代码本身不复杂,抽象下来就是四步:
- 感知输入
- 决策下一步
- 调工具执行
- 把结果喂回去继续循环
所以我现在越来越认同一个判断:
不要把 Agent 的神秘感,误当成架构复杂度。
很多时候,Loop 本体是最稳定、最不该频繁改动的部分。真正会持续变化的,是这些东西:
- 工具集怎么组织
- 状态怎么外化
- 上下文怎么裁剪
- 出错后怎么验证和回滚
- 多 Agent 怎么分工
也就是说,Loop 更像 CPU,系统表现更多取决于外围板卡和总线,而不是 CPU 那十几行控制逻辑。
2. 别把 Workflow 和 Agent 混着叫
Tw93 提到一个很关键的区分:
- Workflow:执行路径由代码预先写死
- Agent:下一步由 LLM 动态决定
这件事看起来像术语洁癖,其实不是。
因为一旦你分不清,就很容易出现两个常见问题:
第一种:明明是 Workflow,硬要包装成 Agent
比如:
- 用户提问后先分类
- 再去固定知识库检索
- 再套固定模板输出
这套流程也许很好用,但它本质上不是 Agent,而是带模型节点的 workflow。
这没问题,问题在于很多团队会因此误判:
- 以为自己已经在做 Agent 平台
- 以为下一步性能问题该靠更强模型解决
- 以为系统不灵活是 prompt 写得不够长
实际上,这类系统的问题通常应该通过流程设计来解,不该扔给模型自由发挥。
第二种:本该 Workflow 的任务,过早放权给 Agent
有些任务根本不需要自主性,比如:
- 固定格式文档生成
- 表单校验
- 数据搬运
- 有明确步骤的部署流程
如果你还是让 Agent 自己决定下一步,通常只会引入额外波动。
所以我现在的建议很简单:
先判断任务需要不需要“动态决策”,再决定要不要上 Agent。
不是所有问题都值得换来自主性。
3. 真正影响上线效果的,往往是 Harness
这篇里我最认同的一段,其实不是 Loop,而是它对 Harness 的强调。
简单说,Harness 就是围绕 Agent 搭起来的那层工程护栏。至少包括:
- 验收基线
- 执行边界
- 反馈信号
- 回退手段
这东西为什么重要?
因为模型只负责“猜下一步”,它不天然知道:
- 什么才算完成
- 完成后怎么验证
- 验证失败要不要继续
- 继续失败什么时候停止
- 改坏了怎么回滚
如果这些都没有外部系统兜住,Agent 就算模型再强,也只是一个高成本随机游走器。
我觉得这也是现在很多 Agent 项目跑不稳的核心原因:
问题不在于模型能力不足,而在于系统没有给它一个机器可执行的“对错判断”。
这在代码场景里尤其明显。
如果你的任务可以自动验证,比如:
- 单测
- E2E
- lint / typecheck
- 构建结果
- 日志/指标/trace 校验
那 Agent 的可用性会直接上一个台阶。
反过来,如果结果只能靠人盯着判断“看起来差不多”,吞吐量上限就永远在人身上。
所以我现在看 Agent 项目,第一反应不是“你用什么模型”,而是先问:
- 这件事能不能自动验收?
- Agent 改完后系统能不能自己知道它改对了?
如果答案是否,那后面很多优化都只是局部修补。
4. Context Rot 比上下文长度更可怕
长上下文不是越长越好,这件事大家都知道。
但很多人还没真的把它当工程问题处理。
文章里提到一个词我很认同:Context Rot。意思是上下文不是不够长,而是越来越烂。
典型症状是:
- 信息越来越多
- 真正重要的信息反而越来越难被注意到
- 无关内容开始稀释决策质量
这时候你会误以为模型不聪明,实际上可能只是喂得太乱。
我现在比较认可的做法,就是把上下文按稳定性和使用频率拆层:
常驻层
只放这些:
- 身份
- 项目硬规则
- 绝对禁止项
- 必须长期成立的约束
它应该短、硬、稳定。
按需加载层
比如 Skill、领域知识、专项操作手册。
描述符常驻,正文触发时再读。
运行时注入层
例如:
- 当前时间
- 当前渠道
- 当前任务上下文
- 当前用户偏好
它们是动态的,不该永久粘在大 prompt 里。
记忆层
跨会话经验写到文件里,需要时检索,不要默认塞进系统提示。
系统层
能写成 hook、规则、校验器的东西,就不要反复让模型读。
这点我现在特别认同:
凡是确定性逻辑,就别放进上下文。
因为上下文适合承载模糊决策,不适合反复模拟 if/else。
5. Skill 最重要的是“像路由”,不是“像说明书”
Tw93 那段关于 Skill 描述的判断,我觉得很实用。
很多人写 Skill,喜欢写成长篇介绍:
- 它能做什么
- 它很强
- 它适合很多很多场景
结果模型反而更容易乱触发。
因为 Skill 真正承担的第一职责不是解释能力,而是帮助路由。
所以一个好 Skill 描述更应该回答的是:
- 什么时候该用我
- 什么时候不要用我
- 我产出的是什么
而不是“我很全面”。
比如下面这种就比长文更有效:
Use when deploying to production or rolling back.Don't use when editing local config only.Outputs: deployment result, verification notes, rollback hints.而且反例特别重要。
没有反例的 Skill,边界通常会漂。
这点我在自己日常使用里也越来越明显地感受到:
- 触发失败,很多时候不是模型不会选
- 而是 Skill 的边界写得不够尖锐
所以如果你想提升 Agent 的稳定性,除了想 prompt,不如先去检查一下 Skill 描述是不是写成了产品介绍页。
6. 工具应该面向目标,不要照搬底层 API
这一点非常关键。
很多工具设计的第一版,都会犯同一个错误:把现有 API 原封不动暴露给模型。
比如你有一套文件系统 API,就给模型这些工具:
create_filewrite_filechmod_filemove_file
从工程师视角看,这没什么问题。
但从 Agent 视角看,太碎了。
因为 Agent 的目标不是“调用某个 endpoint”,而是“完成一个任务”。
所以更合理的抽象应该是:
create_script(path, content, executable)deploy_preview(env, buildId)open_pull_request(branch, title, body)
也就是把底层细碎操作压成目标导向工具。
我现在越来越认同一个原则:
工具不是给人类 SDK 用的,而是给模型形成动作意图用的。
如果一个动作明明总是成组出现,那最好就不要拆成十几个小按钮让模型自己拼。
因为每多一层工具编排自由度,就多一层出错空间。
7. 最适合 Agent 的任务,不是最复杂的任务,而是最容易验证的任务
这点容易反直觉。
很多人会觉得,越复杂越开放的问题,越适合 Agent。
但从工程角度看,恰好相反。
最适合 Agent 发挥的,往往是这类任务:
- 目标清晰
- 输入输出边界明确
- 可以自动验证结果
- 失败后有可观测反馈
比如:
- 修一个有复现步骤的 bug
- 写一个有测试兜底的小功能
- 跑一个有明确 pass/fail 的运维检查
- 做一次规则清晰的代码迁移
而下面这些任务虽然也能做,但波动更大:
- 开放式研究
- 长链路业务策略讨论
- 很依赖隐性审美判断的创意产出
- 多方协商类工作
不是说不能用 Agent,而是这些任务更依赖人类持续介入。
所以我的建议不是“别用 Agent 做难事”,而是:
先把任务推进到“目标清晰 + 能自动验证”的区域,再让 Agent 上场。
Harness 的价值,本质上也是把任务往这个区域推。
我自己从这篇里拿走的 3 个落地建议
如果你不想看完整篇文章,只想知道马上能做什么,我会先做这三件事。
1. 先补验证,再谈自治
在让 Agent 自主执行之前,先补:
- lint / test / build
- 关键操作回滚方案
- 最基本的成功/失败判断信号
没有这些,Agent 只会把问题放大得更快。
2. 把 Skill 描述重写成路由条件
重点不是写多,而是写准:
- Use when
- Don’t use when
- 输出物是什么
- 反例是什么
这一步通常比继续给系统提示加几百 token 更值。
3. 把工具从“接口视角”改成“任务视角”
少暴露底层细粒度操作,多暴露目标导向动作。
你会发现很多所谓“模型选错工具”的问题,其实是工具定义本身就在诱导它犯错。
最后总结
我看完 Tw93 这篇之后,一个更明确的感受是:
Agent 工程的重点,正在从“怎么让模型更聪明”转向“怎么让系统更不脆”。
Loop 当然重要,但它没你想象中那么重要。
真正决定一个 Agent 系统上线后能不能稳定跑的,是这些更偏工程的东西:
- Harness
- Context 分层
- Skill 路由
- 工具抽象
- 自动验证
- 可观测性
如果这些层没补起来,模型升级通常只能带来有限改善。
反过来,只要这些层补得足够扎实,就算不是最贵的模型,系统也可能比你想象中更稳。
这不是在否认模型价值,而是想说:
真正关键的不是只把大脑换贵一点,而是把整套神经系统、感官系统和反馈系统一起搭好。
参考
- Tw93,《你不知道的 Agent:原理、架构与工程实践》:https://x.com/i/status/2034627967926825175
- 读取镜像:https://r.jina.ai/https://x.com/i/status/2034627967926825175